I have worked on a bunch of different AWS projects over the past few years. I focus on deployment and automation. Naturally CDK became quite a powerful tool for me. While every project was different, some requirements kept repeating. Me being me, I created some open-source tools to help me with those repeating requirements so I can write less code in my next project.
Self-Hosted Runners for GitHub Actions
AWS has CodeBuild, CodePipeline, and even CodeCommit (for now). But most projects I worked on preferred GitHub Actions for the nicer UI, well integrated features, and out-of-the-box usability. Eventually most needed a way to use self-hosted runners inside AWS to access some internal database, due to security concerns, or simply because they are using GitHub Enterprise Server. After having to spend a few days trying to get actions-runner-controller on k8s due to a documentation bug, I broke down and created my own solution.
I created cdk-github-runners. I had fun playing with new AWS features, but mostly focused on making it as easy to install as possible. It deploys in a few minutes with the default configuration. After deployment you end up with a fancy browser-based setup wizard. It even uses app manifests to create the GitHub app automatically. This means there is zero room for errors with secrets because you don’t have to copy around multiple random keys and tokens. And then to top it all off, there is a solid API to customize the runner image and add dependencies or configuration. It can create on-demand runners for you on EC2, ECS, Fargate, CodeBuild and even Lambda (because why not?). Runner images are built in AWS itself so you don’t need to wait hours for it to build and upload from your computer. Refreshed images are built on a schedule so you are always up-to-date.
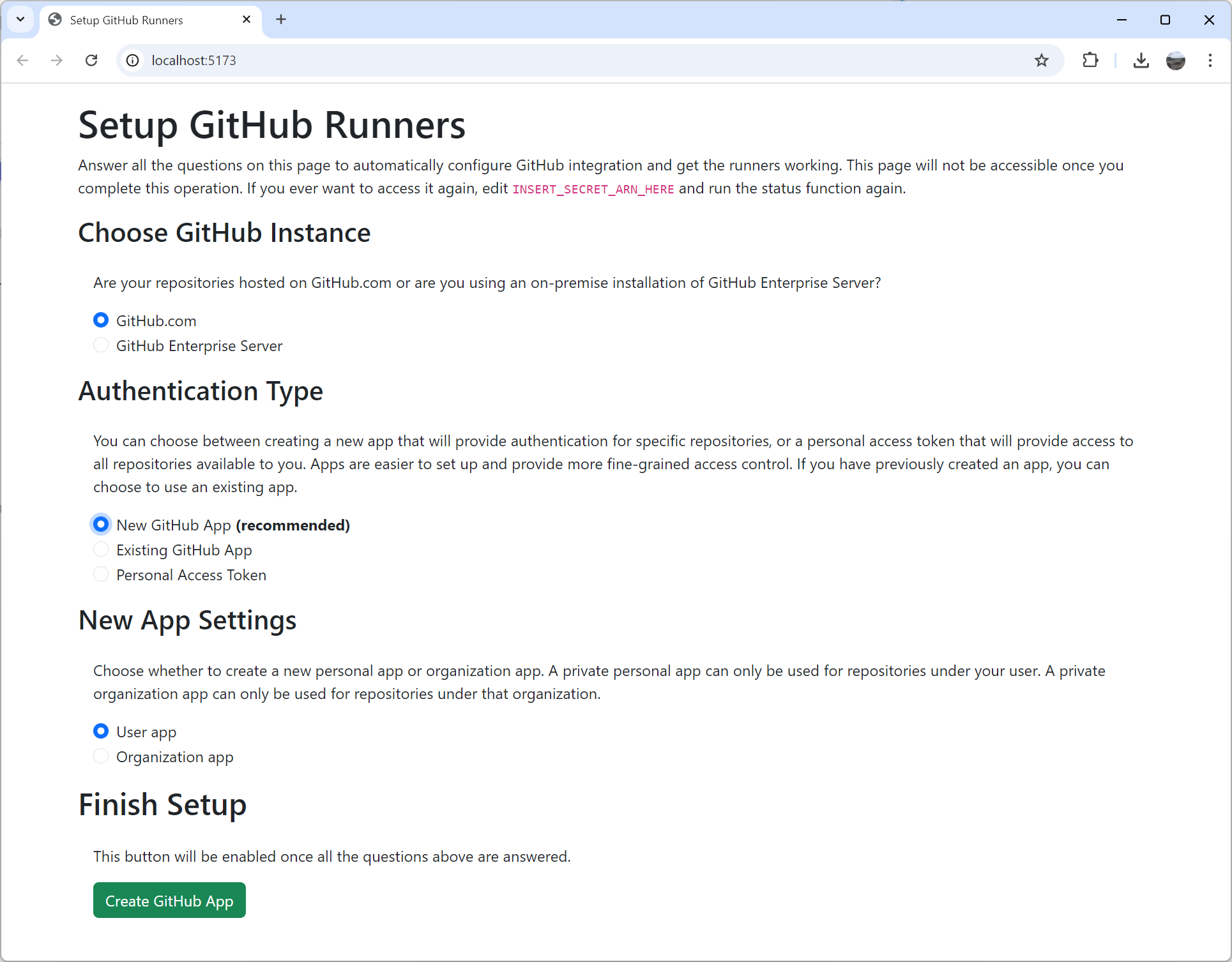
Of all the various open-source tools I’ve worked on over the years, this one has been the most popular so far, second only to NSIS. People want their self-hosted runners. I believe most of the popularity is thanks to Corey Quinn of Last Week in AWS mentioning the tool in his talks. You should hear him talk about it, but I’ll just say he lived up to his name with the architecture of his setup. He even invited me to his podcast to talk about open-source which was a lot of fun.
Turbo-Charging Deployments
No one likes long deployment times. And when working on a laptop, long and resource heavy build processes are even worse. Whenever CDK starts Docker to bundle assets locally, I know it’s time for a coffee break. This is why I created cdk-turbo-layers and used it in every project where Python Lambdas have dependencies. Instead of cooking my poor laptop, it bundles the dependencies in Lambda or CodeBuild on AWS and attaches them as a layer to my functions. The usual CDK process downloads dependencies, installs them, bundles them, and then uploads them right back. But with turbo layers there is no downloading, definitely no uploading, and bundling only happens when dependencies change. Finally CDK only uploads the code itself and absolutely never touches dependencies locally. You can uninstall Docker.
This tool uses the exact same trick I used with Lovage (blog post) and serverless-python-requirements (blog post). While turbo layers got a bit more stars than its ancestors, it’s still not very popular. People really hate layers. And they do have some good reasons. But this tool does the trick for me. I can deploy my projects way faster without Docker cooking my lap.
Just in case you’re curious about the details, all it does is create a custom resource that does the bundling on AWS itself. It creates a Lambda function that runs pip install, zips the result up, uploads it to S3, and returns the hash. A layer is then created based on the result of the custom resource and attached to the function. There is a lot more fluff around it to support different package managers, and provide additional debugging information for the eventual packaging failure. But at the heart of it is just a custom resource call pip install.
Standalone SOCI Indexer for Speed
In the same theme of speeding things up, I have been excited about AWS announcing SOCI support. Lazy loading Docker images for shorter container boot times? Yes please. This is immediately useful in every project I’ve worked on. But while being excited about the technology, I was disappointed to try and fail running it. The basic snapshotter that indexes images so they can use SOCI has some heavy dependencies. I believe it was running containerd on CodeBuild that broke my spirit. I decided to fork their Lambda variant of the snapshotter and create standalone-soci-indexer.
This tool runs anywhere and requires nothing. It doesn’t even require Docker. It can handle arm64 images on x64 and x64 images on arm64. It even almost runs on Windows (gzip binding is missing). It is completely standalone and impossible to install wrong as it’s just one executable. Download it, run it, and you got yourself a SOCI index. Done.
