Testing on production data is very useful to root out real-life bugs, take user behavior into account, and measure real performance of your system. But testing on production databases is dangerous. You don’t want the extra load and you don’t want the potential of data loss. So you make a copy of your production database and before you know it has been two years, the data is stale and the schema has been manually modified beyond recognition. This is why I created RDS-sanitized-snapshots. It periodically takes a snapshot, sanitizes it to remove data the developers shouldn’t access like credit card numbers, and then optionally share with other AWS accounts.
As usual it’s one CloudFormation template that can be deployed in one step. The template is generated using Python and troposphere.
There are many examples around the web that do parts of this. I wanted to create a complete solution that doesn’t require managing access keys and can be used without any servers. Since all of the operations take a long time and Lambda has a 15 minutes time limit, I decided it’s time to play with Step Functions. Step Functions let you create a state machine that is capable of executing Lambda functions and Fargate tasks for each step. Defining retry and wait logic is also built-in so there is no need for long running Lambda functions or EC2 instances. It even shows you the state in a nice graph.
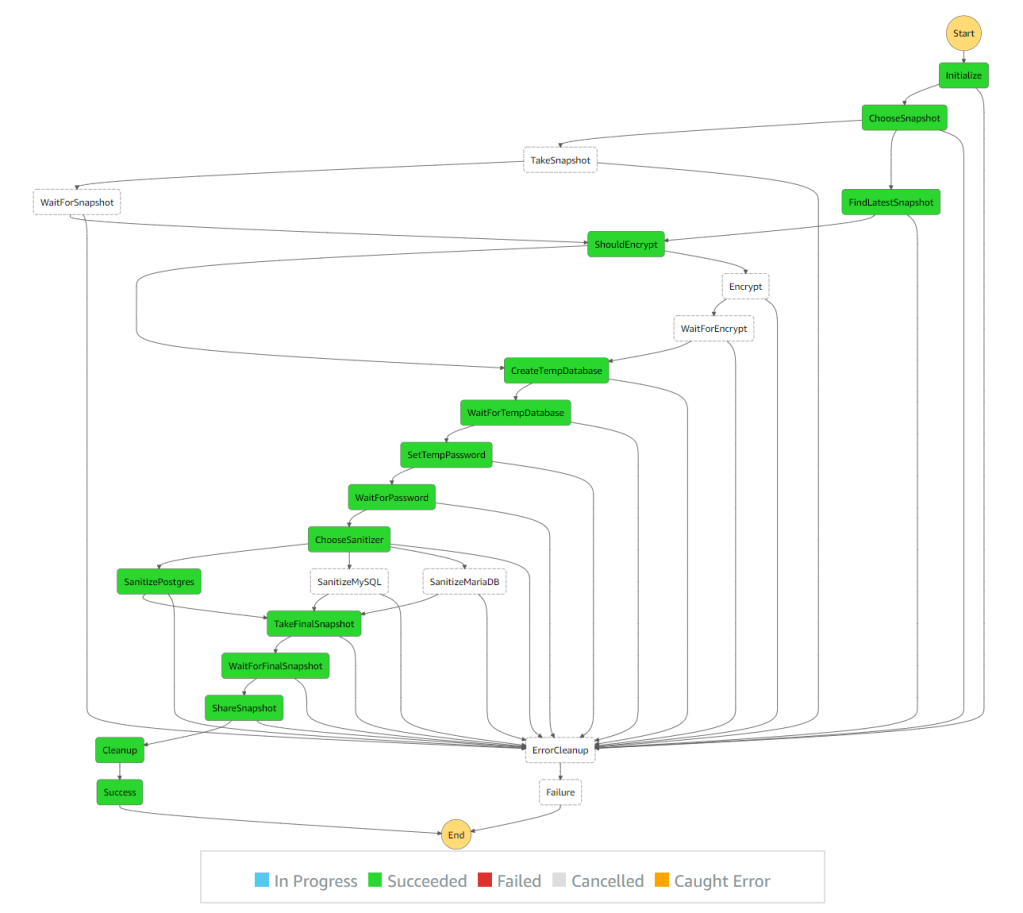
To create a sanitized snapshot we need to:
- Create a temporary copy of the production database so we don’t affect the actual data or the performance of the production system. We do this by taking a snapshot of the production database or finding the latest available snapshot and creating a temporary database from that.
- Run configured SQL queries to sanitize the temporary database. This can delete passwords, remove PII, etc. Since database operations can take a long time, we can’t do this in Lambda due to its 15 minutes limit. So instead we create a Fargate task that connects to the temporary database and executes the queries.
- Take a snapshot of the temporary database after it has been sanitized. Since this process is meant to be executed periodically, the snapshot name needs to be unique.
- Share snapshot with QA and development accounts.
- Clean-up temporary snapshots and databases.
If the database is encrypted we might also need to re-encrypt it with a key that can be shared with the other accounts. For that purpose we have a KMS key id option that adds another step of copying the snapshot over with a new key. There is no way to modify the key of an existing database or snapshot besides when copying the snapshot over to a new snapshot. Sharing the key is not covered by this solution.

The step function handles all the waiting by calling the Lambda handler to check if it’s ready. If it is ready, we can move on to the next step. If it’s not ready, it throws a specific NotReady exception and the step function retries in 60 seconds. The default retry parameters are maximum of 3 retries with each wait twice as long as the previous one. Since this is not a real failure but an expected one, we can increase the number of retries and remove the backoff logic that doubles the waiting time.
{
"States": {
"WaitForSnapshot": {
"Type": "Task",
"Resource": "${HandlerFunction.Arn}",
"Parameters": {
"state_name": "WaitForSnapshot",
},
"Next": "CreateTempDatabase",
"Retry": [
{
"ErrorEquals": [
"NotReady"
],
"IntervalSeconds": 60,
"MaxAttempts": 300,
"BackoffRate": 1
}
]
}
}
}
One complication with RDS is networking. Since databases are not accessed using AWS API (and RDS Data API only supports Aurora), the Fargate task needs to run in the same network as the temporary database. We can theoretically create the temporary database in the same VPC, subnet and security group as the production database. But that would require modifying the security group of the production database and can pose a potential security risk or data loss risk. It’s better to keep the temporary and production databases separate to avoid even the remote possibility of something going wrong by accident.
Another oddity I’ve learned from this is that Fargate tasks with no route to the internet can’t use Docker images from Docker Hub. I would have expected the image pulling to be separate from the execution of the task itself like it was with AWS Batch, but that’s not the case. This is why the Fargate task is created with a public facing IP. I tried using Amazon Linux Docker image from ECR, but even that requires an internet route or VPC Endpoint.
All the source code is available on GitHub. You can open an issue or comment here if you have any questions.
